Flite Velocity
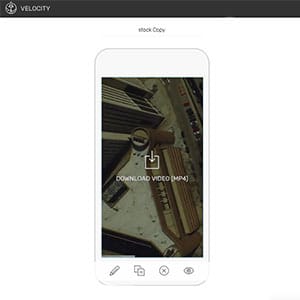
Vertical Video creation in your web browser. JavaScript, React, CSS, Java, JSP, Git
Vertical Video creation in your web browser. JavaScript, React, CSS, Java, JSP, Git
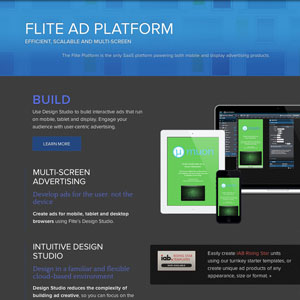
Web-based application for creating rich-media. JavaScript, React, HTML, CSS, Java, JSP, Node, Git
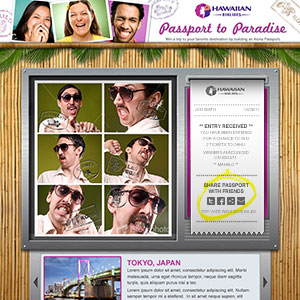
Social campaign featuring user generated content. Flash, JavaScript, HTML, CSS, PHP, Amazon S3, SVN
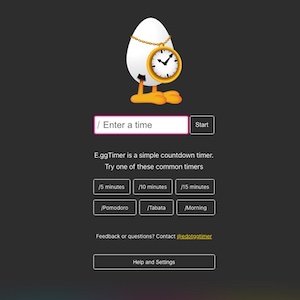
Browser-based countdown utility. JavaScript, HTML, CSS, PHP, Amazon EC2

Web widget hosting and development company. Flash, JavaScript, HTML, PHP

Things I've done in my spare time. Hammer, glue, wood, cardboard, solder.

Hello. I am a Software Engineer at Wiith where I am Frontend Software Engineer doing Web and iOS programming. I used to lead the Content Creation engineering team at Snapchat. I do silly side projects and make memes in Photoshop.
© 2023 Davey LeMieux